ЭѕКщЦН
еЊ вЊ ЪдбщЬсГіСЫвЛжжзюаЁЖўГЫжЇГжЯђСПЛњЕФжэбЊЗЂНЭжЦБИаЁыФЕФЫЎНтЖШдЄВтаТФЃаЭЁЃвдНгжжСПЁЂЗЂНЭЮТЖШЁЂЗЂНЭЪБМфШ§ИіЙЄвеВЮЪ§ЮЊЪфШыЃЌЫЎНтЖШЮЊЪфГіЃЌЭЈЙ§е§НЛЪдбщЛёЕУЪ§ОнбљБОЁЃвдЪдбщЪ§ОнЮЊЛљДЁЃЌНЈСЂзюаЁЖўГЫжЇГжЯђСПЛњФЃаЭЃЌРћгУФЃаЭдЄВтжэбЊЗЂНЭжЦБИаЁыФЕФЫЎНтЖШЁЃИУЗНЗЈОпгаНЈФЃЫйЖШПьЁЂдЄВтОЋЖШИпЁЂВйзїМђБуЕШгХЕуЃЌВЛНіПЫЗўСЫГЃЙцЕФBPдЄВтФЃаЭЕФВЛзуЃЌЖјЧвадФмгХгкБъзМжЇГжЯђСПЛњдЄВтФЃаЭЁЃ
ЙиМќДЪ жэбЊЗЂНЭЃЛаЁыФЃЛЫЎНтЖШЃЛдЄВтФЃаЭЃЛзюаЁЖўГЫжЇГжЯђСПЛњ
жаЭМЗжРрКХ Q516
жэбЊвЛАувдбЊЗлЕФаЮЪНЬэМгЕНЫЧСЯжаЃЌЕЋвђбЊЗлжаЕААзжЪЗжзгСПДѓЃЌЖЏЮяФбвдЯћЛЏЃЌЧвЪЪПкадВюЁЃРћгУЮЂЩњЮяВњЩњИДКЯУИЕФЬиадНјааЗЂНЭДІРэЃЌФмгааЇНЕНтбЊвКжаЕФДѓЗжзгЕААзжЪЃЌДгжаЬсШЁЙІФмадаЁыФЃЌДѓДѓЬсИпбЊЗлЕФЯћЛЏТЪЃЌгааЇРћгУгаЯоЕФЕААзжЪзЪдДЁЃжэбЊЗЂНЭжЦБИаЁыФЕФЙиМќЪЧЙЄвеЫЎЦНПижЦКЭЩњВњаЇТЪЕФЬсИпЃЌЖјПЦбЇЁЂПЩППЕиЙРМЦжэбЊЗЂНЭжЦБИаЁыФЕФЫЎНтЖШЃЌЖдгХЛЏЙЄвеВЮЪ§ЩшМЦКЭЬсИпЩњВњаЇТЪОпгаживЊвтвхЁЃШЛЖјдкжэбЊЗЂНЭжЦБИаЁыФЙ§ГЬжаЃЌгЩгкЫЎНтЖШгыЗЂНЭЙЄвеВЮЪ§ГЪИДдгЕФЗЧЯпадЙиЯЕЃЌДЋЭГЕФдЄВтЗНЗЈДцдкОЋЖШЕЭЁЂВйзїИДдгЁЂжмЦкГЄЁЂаЇТЪЕЭЕШШБЕуЃЌФбвдТњзуЪЕМЪЩњВњЕФашвЊЁЃНќФъРДЃЌаэЖрбЇепНЋШЫЙЄЩёОЭјТч(artificial neural networkЃЌANN)ММЪѕдЫгУгкдЄВтжэбЊЗЂНЭжЦБИаЁыФЫЎНтЖШЃЌШЁЕУСЫвЛЖЈЕФЭЛЦЦЁЃЫќОпгаДѓЙцФЃЕФВЂааДІРэКЭЗжВМЪНЕФаХЯЂДцДЂФмСІЁЂСМКУЕФздЪЪгІадЁЂздзщжЏадМАКмЧПЕФбЇЯАЁЂСЊЯыЁЂШнДэКЭПЙИЩШХФмСІЃЌФмвдШЮКЮОЋЖШБЦНќИДдгЗЧЯпадЯЕЭГЃЌЛёЕУНЯИпЕФдЄВтОЋЖШКЭдЄВтаЇТЪЃЌЕЋвВДцдкЯШЬьадВЛзуЃЌШчНЈСЂФЃаЭЪБДцдкзХЭјТчФкВПЕЅдЊвтвхВЛУїШЗЁЂбЕСЗЪБМфГЄЁЂвзЯнШыОжВПМЋжЕЕуЁЂЭтВхФмСІШѕЁЂЗКЛЏФмСІЕЭЕШШБЕуЁЃжЇГжЯђСПЛњ(Support Vector MachineЃЌSVM)ЪЧгЩЭГМЦбЇЯАРэТлЗЂеЙЦ№РДЕФвЛжжаТаЭбЇЯАЛњЦїЃЌЫќвдНсЙЙЗчЯезюаЁЛЏдРэЮЊЛљДЁЃЌОпгаНЯЧПЕФбЇЯАЗКЛЏФмСІЃЌЬиБ№ЪЧЖдаЁбљБОЪ§ОнЕФФЃЪНЪЖБ№КЭКЏЪ§ЙРМЦОпгаГіЩЋЕФбЇЯАЭЦЙуадФмЃЌПЫЗўСЫANNНсЙЙвРРЕЩшМЦепОбщЕФШБЕуЃЌНЯКУНтОіСЫИпЮЌЪ§ЁЂОжВПМЋаЁЁЂаЁбљБОЕШЛњЦїбЇЯАЮЪЬтЁЃзюаЁЖўГЫжЇГжЯђСПЛњ(Least Square SVMЃЌLS-SVM)ЪЧБъзМSVMЕФвЛжжаТРЉеЙЃЌЫќгУЕШЪНдМЪјДњЬцБъзМSVMЕФВЛЕШЪНдМЪјЃЌНЋЖўДЮЙцЛЎЮЪЬтзЊЛЏЮЊЯпадЗНГЬзщЧѓНтЃЌНЕЕЭСЫМЦЫуИДдгадЃЌОпгаИќПьЕФЧѓНтЫйЖШКЭИќКУЕФТГАєадЁЃБОЮФГЂЪдгУзюаЁЖўГЫжЇГжЯђСПЛњЙРМЦКЭдЄВтжэбЊЗЂНЭжЦБИаЁыФЕФЫЎНтЖШЃЌШЁЕУСЫНЯКУЕФаЇЙћЁЃ
1 жэбЊЗЂНЭжЦБИаЁыФЫЎНтЖШдЄВт
1.1 ВФСЯгыЗНЗЈ
1.1.1 жївЊВФСЯ
A32ОњжъЃЈЮфККРэЙЄДѓбЇЩњЮяЙЄГЬЪЕбщЪвЩИбЁБЃДцЃЉЃЛаТЯЪжэбЊ(ЮфККШтСЊГЇЃЌЭРдзКѓ30 minвдФкЪеМЏЕФ)ЃЛШ§ТШввЫсЃЈЩЯКЃЩНЦжЛЏЙЄгаЯоЙЋЫОЃЌЗжЮіДПЃЉЃЛЦфЫќЪдМСЮЊЪЕбщЪвГЃгУЪдМСЁЃ
1.1.2 жївЊвЧЦїгыЩшБИ
HZQЁЊCаЭКуЮТеёЕДЦїЃЈЙўЖћБѕЖЋСЊЕчзгЙЋЫОЃЉЃЛHPSЁЊ280аЭЩњЛЏХрбјЯфЃЈЙўЖћБѕЖЋСЊЕчзгЙЋЫОЃЉЃЛAR2140аЭЕчзгЬьЦНЃЈАТКРЫЙЙњМЪУГвзЙЋЫОЃЉЃЛCF16RX аЭРфЖГРыаФЛњЃЈHitachi KokiЙЋЫОЃЉЃЛПЪЯЖЈЕЊвЧЃЈББОЉШ№РћЗжЮівЧЦїЙЋЫОЃЉЁЃ
1.1.3 ЪдбщЗНЗЈ
1.1.3.1 ЕААзжЪКЌСПЕФВтЖЈ
ВЩгУАыЮЂСППЪЯЖЈЕЊЗЈЁЃ
1.1.3.2 Ш§ТШввЫс(TCA)ПЩШмЕЊЕФВтЖЈ
дк10 mlжэбЊЗЂНЭвКжаМгШы10%Ш§ТШввЫсШмвК10 mlЃЌЛьдШКѓОВжУ30 minЃЌ11 000 r/minРыаФЃЌЮТЖШЮЊ4 ЁцЃЌЪБМфЮЊ15 minЁЃВЩгУАыЮЂСППЪЯЖЈЕЊЗЈВтЖЈЩЯЧхвКжаЕЊЕФКЌСПЁЃ
1.1.3.3 ЫЎНтЖШ DH ЕФВтЖЈ

ЪНжаЃКAЁЊЁЊжэбЊЗЂНЭКѓШ§ТШввЫсЃЈTCAЃЉПЩШмЕЊКЌСПЃЛ
BЁЊЁЊжэбЊЗЂНЭЧАШ§ТШввЫсЃЈTCAЃЉПЩШмЕЊКЌСПЃЛ
CЁЊЁЊжэбЊЗЂНЭЧАзмЕЊКЌСПЁЃ
1.1.4 ЪдбщЩшМЦ
гАЯьжэбЊЗЂНЭЗЈжЦБИаЁыФВњГіКЭЗжзгГЄЖШЕФЗЂНЭЙЄвеВЮЪ§НЯЖрЃЌШчЗЂНЭЪБМфЁЂЮТЖШЁЂНгжжСПЁЂЦ№ЪМpHжЕЁЂзАСЯСПЕШЁЃИљОнгАЯьГЬЖШЁЂЯжгаЬѕМўЁЂЩњВњОбщЃЌБОЮФбЁШЁЦфжаЕФНгжжСПЁЂЗЂНЭЮТЖШЁЂЗЂНЭЪБМфШ§ИівђЫиЮЊжївЊгАЯьЖдЯѓЃЌвдЫЎНтЖШDHЮЊЗЂНЭжЦБИаЁыФаЇЙћжИБъЃЌВЩгУЖўДЮЛиЙща§зЊзщКЯЩшМЦЃЌЪдбщвђЫигыЫЎЦНЕФШЁжЕМћБэ1ЁЃЙВЩшСЂ23ИіДІРэзщЃЌЦфжаСуЫЎЦНЙВга9ИіДІРэзщЃЌВЛЩшжиИДЃЛЩЯЯТЫЎЦНДІРэзщУПзщЩш 5ИіжиИДЃЛЦфгрДІРэзщУПзщЩш3ИіжиИДЃЌЪдбщЩшМЦгыНсЙћМћБэ2ЃЈЦфжааТЯЪжэбЊNзмКЌСП30.07%ЃЛаТЯЪжэбЊTCAПЩШмЕЊКЌСП0.83%ЃЉЁЃ

1.2 НЈСЂLS-SVMФЃаЭ
вдНгжжСП(%)ЁЂЗЂНЭЮТЖШ(Ёц)ЁЂЗЂНЭЪБМф(h)ЮЊЪфШыСПЃЌЫЎНтЖШ(%)ЮЊЪфГіСПЃЌНЈСЂLS- SVMЯЕЭГЃЌВЩгУОЖЯђЛљКЫКЏЪ§ЁЃФЃаЭадФмЦРМлжИБъВЩгУЦНОљЮѓВюМЦЫуЙЋЪНЃК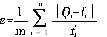
ЪНжаЃКQiЁЊЁЊЮЊЪЕМЪЕФВтСПжЕЃЛ
fiЁЊЁЊдЄВтжЕЃЛ
mЁЊЁЊбщжЄДЮЪ§ЁЃ
КЫПэЖШ?звЁЂГЭЗЃЯЕЪ§ІУЪЧНЈСЂLS-SVMФЃаЭЕФживЊЮЪЬтЁЃ?звКЭІУЕФбЁдёЭЈГЃВЩгУНЛВцбщжЄЗНЗЈЃЌЕЋЪЧНЛВцбщжЄЗНЗЈгЩгк?звКЭІУЕФВЮЪ§МЏВЮЪ§гаЯоЕФдвђЃЌОГЃГіЯжВЛФмТњзуДяЕНЮѓВюОЋЖШЕФЧщПіЁЃЮЊДЫЃЌБОЮФВЩгУвЛжжздЪЪгІЕФ?звКЭІУбЁдёРДНЈСЂLS-SVMФЃаЭЃЌОпЬхВНжшМћЭМ1ЁЃ
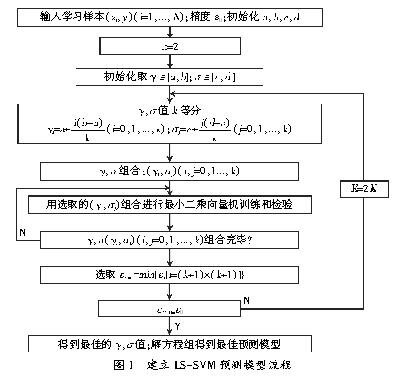
вдБэ2жаЪдбщЪ§ОнЕФвЛВПЗжзїЮЊбЕСЗбљБОЃЌЖдЯЕЭГНјаабЕСЗЃЌСэвЛВПЗжЃЈ3ЁЂ6ЁЂ9ЁЂ12ЁЂ15ЁЂ18ЃЉСєзїВтЪдбљБОЖдЯЕЭГНјааВтЪдЁЃВНжшШчЯТЃКЂйЪфШыбЕСЗбљБОЃЛЂкбЁЖЈОЖЯђЛљКЫКЏЪ§ЃЌГѕЪМЛЏКЫПэЖШ?звКЭГЭЗЃвђзгІУЃЛЂлАДздЪЪгІбЁдёЗНЗЈЧѓНтКЫПэЖШ?звКЭГЭЗЃвђзгІУЃЛЂмИљОнLS-SVMЫуЗЈЧѓНтЛиЙщВЮЪ§aКЭbЃЛЂнНЋФЃаЭВЮЪ§в§ШыLS-SVMдЄВтЛњ,ЪфШыВтЪдбљБОдЄВтЫЎНтЖШЁЃ
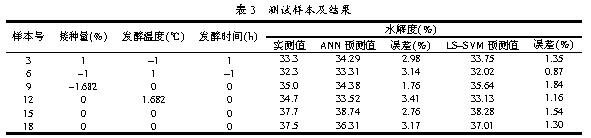
LS-SVMФЃаЭВтЪдНсЙћМћБэ3ЃЌзюДѓдЄВтЮѓВюаЁгк2.0%ЃЌЦНОљЮѓВюЮЊ1.34%ЁЃЮЊСЫМьбщБОЮФдЄВтЗНЗЈгыЩёОЭјТчдЄВтЗНЗЈЕФадФмЃЌЩшМЦвЛИіBPЩёОЭјТчЃЌЭјТчНсЙЙ3-8-1ЁЃANNФЃаЭдЄВтЕФНсЙћМћБэ3ЃЌзюДѓдЄВтЮѓВюДѓгк3%ЃЌЦНОљЮѓВюЮЊ2.87%ЃЌетБэУїБОЮФLS-SVMдЄВтФЃаЭОЋЖШЯджјЬсИпЃЌЭЌЪБЃЌLS-SVMдЄВтФЃаЭбЇЯАбЕСЗЪБМфДѓДѓЫѕЖЬЃЌНіЮЊANNФЃаЭЕФЧЇЗжжЎвЛЁЃМИжждЄВтЗНЗЈЕФНсЙћБШНЯМћЭМ2ЁЃ
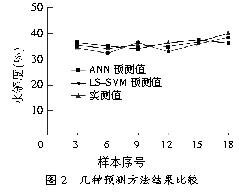
2 Нсгя
дкжэбЊЗЂНЭжЦБИаЁыФЩњВњжаЃЌКмФбгУОЋШЗЕФЪ§бЇФЃаЭУшЪіЙЄвеЬѕМўгыаЁыФВњСПжЎМфЕФИДдгЙиЯЕЃЌДгЖјОЋШЗдЄВтЫЎНтаЇЙћЃЌНјааЙЄвегХЛЏКЭЬѕМўИФНјЁЃШЫЙЄжЧФмММЪѕдЄВтжэбЊЗЂНЭжЦБИаЁыФЫЎНтЖШЃЌЮоаыжЊЕРИїИіЙЄвевђЫигыЫЎНтЖШжЎМфЕФЪ§бЇЙиЯЕЙЋЪНЃЌЮЊжэбЊЗЂНЭжЦБИаЁыФЩњВњОіВпКЭЙмРэЬсЙЉСЫвЛИіаТЕФЪжЖЮЁЃзюаЁЖўГЫжЇГжЯђСПЛњгЩгкНЋЧѓНтЖўДЮЙцЛЎЮЪЬтзЊЛЏЮЊЧѓНтЯпадЗНГЬЃЌЪЧзюЭъЩЦЕФдЄВтКЭЪЖБ№ШЫЙЄжЧФмММЪѕЃЌЫќВЛНіЪЪКЯаЁбљБОзДЬЌЯТЕФЛњЦїбЇЯАЮЪЬтЃЌЖјЧвадФмгХгкБъзМSVMКЭANNЁЃдкНЈФЃЪБМфЩЯвЛАуБШSVMЗНЗЈЫѕЖЬ1~2ИіЪ§СПМЖЃЌБШANNЗНЗЈПЩЫѕЖЬ2~3ИіЪ§СПМЖЃЌЖјдЄВтОЋЖШвЊБШSVMБъзМФЃаЭИп0.5ЁЋ0.6БЖЃЌБШANNФЃаЭИп1~2БЖЁЃвђДЫЃЌРћгУзюаЁЖўГЫжЇГжЯђСПЛњдЄВтжэбЊЗЂНЭжЦБИаЁыФаЇЙћЃЌОпгаживЊЕФРэТлКЭЯжЪЕвтвхЁЃ
ЃЈВЮПМЮФЯзШєИЩЦЊЃЌПЏТдЃЌашепПЩКЏЫїЃЉ
ЃЈБрМЃКСѕУєдОЃЌЃЉ
ЭѕКщЦНЃЌЮфККРэЙЄДѓбЇЩњЮягыжЦвЉЙЄГЬбЇдКЃЌВЉЪПЃЌНЬЪкЃЌ430074ЃЌКўББЪЁЮфККЪаКщЩНЧјЛЦН№ЩНТЗ1КХЁЃ
ЪеИхШеЦкЃК2007-07-30 |














